
Performance testing helps teams answer an important question: Can our system handle the traffic we expect? Stress testing answers a more uncomfortable but far more valuable question: What happens when reality doesn't match our expectations?
In production, systems are rarely stressed in neat, predictable ways. Traffic spikes without warning. Dependencies slow down. Background jobs overlap with peak usage. Auto-scaling reacts too late. And suddenly, a system that looked "green" in dashboards starts behaving in ways no one anticipated.
This is where stress testing plays a critical role within performance testing — not to prove how fast a system is, but to reveal how it behaves when pushed beyond its limits.
Where Stress Testing Fits in Performance Testing
Performance testing is an umbrella that includes different types of tests, each with a specific goal:
- Load testing checks how the system behaves under expected traffic.
- Endurance testing looks at stability over time.
- Spike testing evaluates sudden increases in load.
Stress testing sits at the edge of all of these.
Its purpose is to intentionally exceed the system's designed capacity and observe:
- Where the system breaks
- What fails first
- How failures spread
- Whether the system can recover on its own
In other words, stress testing focuses less on performance metrics and more on failure behavior. It's not about tuning response times; it's about understanding risk.
Performance testing is an umbrella that includes different types of tests, each with a specific goal, for a full breakdown of each category, see our guide on the types of performance testing
Why Stress Testing Goes Beyond Metrics
During normal performance testing, teams rely heavily on numbers like response time, throughput, and CPU usage. These metrics are useful — until the system reaches its breaking point.
Under extreme load:
- Response time becomes irrelevant because requests fail outright
- Resource usage spikes in non-linear ways
- Queues grow faster than they can be processed
- Small delays turn into large-scale outages
Stress testing shifts the focus from how fast the system is to how it fails. Does it degrade gracefully? Does it protect critical functionality? Or does one failure cascade into many?
These are the answers that matter during real incidents.
During normal performance testing, teams rely heavily on numbers like response time, throughput, and CPU usage, these metrics are useful until the system reaches its breaking point.
What Stress Testing Reveals That Load Testing Often Misses
A system can pass all its load tests and still fail spectacularly in production. That's because load testing validates behavior under expected conditions, while stress testing exposes behavior under unexpected ones.
Stress testing often uncovers:
- Hidden bottlenecks that only appear at extreme scale
- Resource exhaustion (threads, memory, database connections)
- Retry logic that amplifies failures instead of handling them
- Dependency limits that cap scalability
- Slow or unstable recovery after overload
These issues rarely surface when traffic increases gradually and stays within safe limits.
How Systems Typically Fail Under Extreme Load
When systems are stressed beyond capacity, failures usually follow recognizable patterns.
Application-Level Failures
At the application layer, thread pools are often the first constraint. As dependencies slow down, threads block while waiting for responses. Once thread pools are exhausted, the application stops accepting new requests — even if CPU and memory still look healthy.
Memory issues also surface quickly under stress. Objects accumulate faster than garbage collection can keep up. Caches grow without proper eviction. Session data expands. Eventually, the application either crashes or degrades to the point of unusability.
Unhandled exceptions become more frequent as edge cases turn into common cases. Timeout handling, race conditions, and retry logic all behave differently under sustained pressure.
Infrastructure-Level Failures
Infrastructure components have limits too — limits that stress testing exposes clearly.
Auto-scaling often reacts slower than teams expect. New instances take time to provision, configure, and warm up. By the time additional capacity is available, existing instances may already be overloaded or failing.
In containerized environments, stress can trigger repeated restarts. Out-of-memory kills, failed health checks, and orchestration overhead can reduce capacity instead of increasing it.
Load balancers can also become bottlenecks. Connection limits, uneven traffic distribution, or SSL termination overhead can cause failures even when backend services are still running.
Dependency and Third-Party Failures
External dependencies are frequently the weakest link during stress.
Databases often have fixed connection pool limits that don't scale with application instances. As traffic increases, connections are exhausted, causing everything upstream to slow down or fail.
Third-party APIs enforce rate limits. When these limits are exceeded, requests are throttled or rejected. Without proper handling, retries can flood the system and worsen the problem.
Payment gateways, authentication providers, and notification services may also slow down under heavy load, introducing failures that ripple through the application.
Stress testing makes these constraints visible before they impact real users.
What This Stress Test Reveals in a Real Scenario
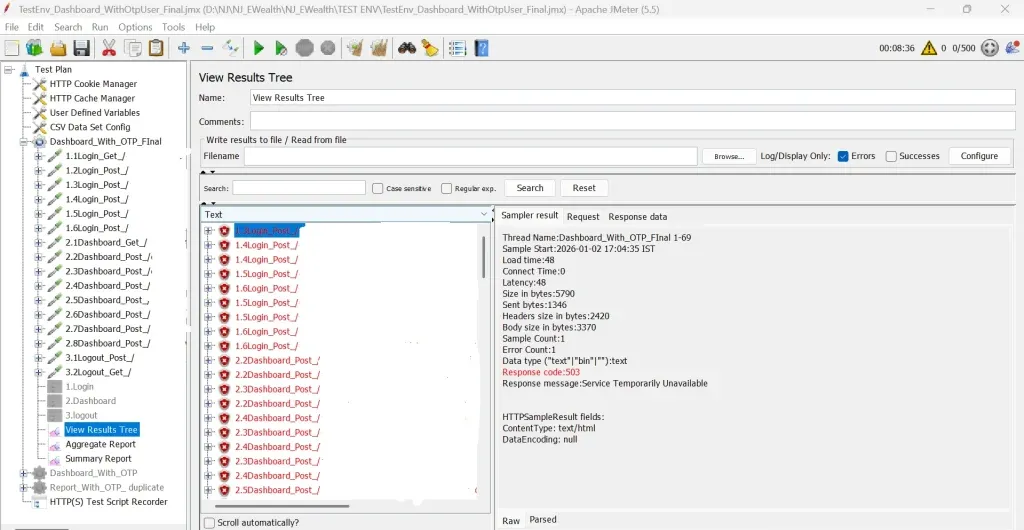
If your application is designed to handle around 250 users at a time, stress testing means intentionally going beyond that limit to see how the system behaves.
For example, you may run tests with:
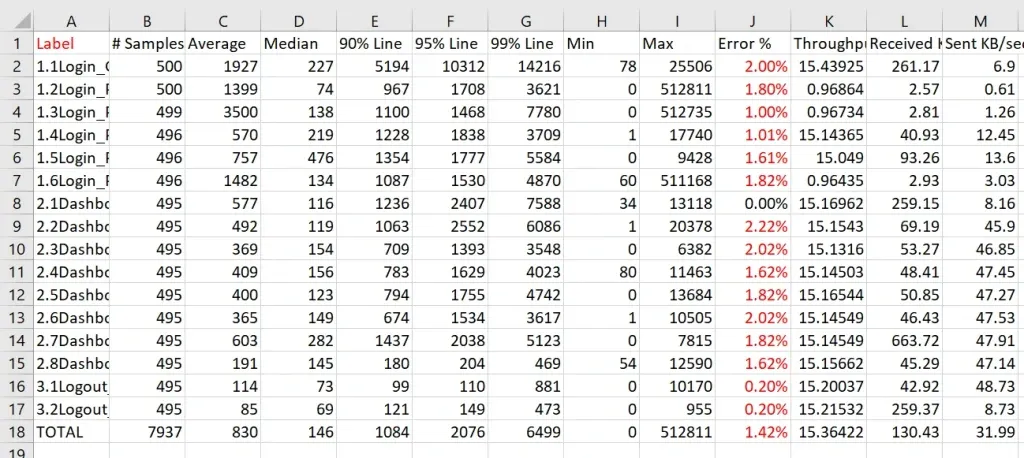
| User Count | Goal |
|---|---|
| 500 users | See when performance starts degrading |
| 1,000 users | Identify which services begin failing |
| 2,000 users | Understand the system's breaking point and recovery behavior |
This helps teams see where the system slows down, where it breaks, and how it recovers — instead of finding out during real traffic spikes.
What Teams Usually Observe During This Test
As the user count increases:
- Response times may suddenly spike instead of increasing gradually
- Some features (like dashboards or reports) fail before others
- Errors such as 503 (Service Unavailable) start appearing
- The system may recover slowly even after traffic drops
This helps teams pinpoint which part of the application needs scaling or optimization first.
When Stress Testing Delivers the Most Value
Stress testing is most effective when performed at the right time. It's especially valuable:
- Before major releases or architectural changes
- Before high-risk traffic events like launches or sales
- After introducing new dependencies or infrastructure changes
Stress testing too early can be misleading. If the architecture isn't stable, data volumes are unrealistic, or environments don't resemble production, the results won't reflect real risks.
The goal is to test realistic systems under extreme but plausible conditions.
Load testing checks expected traffic, but it doesn't show how systems behave when limits are crossed. Understanding the difference between stress and load testing helps teams prepare for real-world traffic spikes and failure scenarios. difference between stress and load testing
Final Thoughts
Stress testing in performance testing isn't about chasing big numbers or proving that your system can survive extreme conditions on paper. It's about understanding what really happens when things don't go as expected.
In real production environments:
- Traffic doesn't arrive neatly
- Dependencies don't always respond on time
- Systems don't get the luxury of failing one component at a time
That's exactly where stress testing proves its value. It shows how your application behaves when limits are crossed, which parts struggle first, and whether the system can recover on its own or needs manual intervention.
Most outages don't happen because systems can't handle normal traffic. They happen when sudden spikes, slow third-party services, or resource exhaustion push systems beyond their comfort zone. Load testing alone can't uncover these situations, but stress testing can.
Stress testing is becoming a key part of the future of performance testing, with a stronger focus on resilience and recovery.
Stress testing is becoming a key part of the future of performance testing, with what's next after load testing placing a stronger focus on resilience and recovery.
At PrimeQA Solutions, we help teams identify breaking points early, understand failure behavior, and strengthen systems before those issues reach production. Our stress and performance testing services are designed to fit real-world traffic patterns, not ideal ones.
If you'd like to understand how your system behaves under pressure — and what to improve before the next spike — we're here to help.